Chapter 7 Statistical Analysis
7.1 Basic Statistical Concepts
7.1.1 Introduction to Descriptive Statistics
- Mean, Median and Mode
Mean is the sum of all values divided by the number of values in the set. It also referred to as average.
Median is the middle value when values in a data set is ordered/lined up in ascending/descending order.
Mode is the number that occurs most in the data set. Simply, the most frequent value in the data set.
All these, are measures of central tendency. Central tendency identifies the center or typical value of a data set. Measuring central tendency summarizes the data by identifying skewness, distribution and how the data is robust to outliers. Business calculate the central tendencies like average sales, median customer age to make informed decision-making.
Below is the formula to calculate mean.
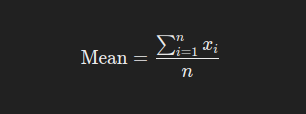
where xi represents each value in the data set, and n is the number of values. Lets calculate mean of the vector ages with the values 12, 58, 27, 33, 31, 27, 37 manually with the steps below;
# Add the values together
total_age = 12 + 58 + 27 + 33 + 31 + 27 + 37
total_age # is 225
number_of_values = 7 # there are 7 values
mean age = total_age/number_of_values
mean_age # is 32.14The average age is 32.14.
To calculate the median of the vector ages, the ages are arranged in descending/ascending order and the middle one is selected. In this case we will line them up in ascending order
# Line the ages up in ascending order
12, 27, 27, 31, 33, 37, 58
# There are 7 ages, the fourth one from either side is the median value
# The median age is 31To find mode, you just find the value that appears the most, for the values 12, 27, 27 , 31, 33, 37, 58, age 27 appears twice while these other ages appear once. The value 27 is therefore the mode.
Mean, median and mode can also be calculated using Base R using the functions mean(), median() and mode() where the vector ages is the argument.
## [1] 32.14286## [1] 31## [1] "numeric"Practical exercise
Load the inbuilt iris R data set, retrieve the sepal width(Sepal.Width) and sepal length(Sepal.length) of the each Iris species and store in separate vectors. For instance, the sepal width for setosa should be in a variable setosa.sepal.width. Finally calculate and interpret the mean, median and mode for each vector
- Variance and Standard deviation
Variance is statistical measure of dispersion that defines how spread the data points are in a data set in relation to the mean of the data set. Standard deviation is the measure of how data is clustered around the mean. It is simply defined to as the square root of variance.
Variance and standard deviation can be calculated in R environment using var() and sd() functions respectively.
Lets create a vector of weights of the athletes in kilograms and calculate the variance and standard deviation.
# Sample vector
athlete_weights = c(55, 76, 52, 68, 71, 63, 58, 52, 85, 96)
# Calculate variance
var(athlete_weights)## [1] 216.7111## [1] 14.72111Practical exercise
Using the same iris data set, calculate the variance and standard deviation for the versicolor species petal width(Petal.Width).
- Range and Interquartile Range
Range is the difference between the maximum and minimum values in the data set. This defines the spread and dispersion of a data set.
Below is the formula for Range:
Range = Maximum Value - Minimum Value
Lets use the weights vector above to calculate the range;
weights = 55, 76, 52, 68, 71, 63, 58, 52, 85, 96
maximum_weight = 96
minimum_weight = 52
Range = maximum_weight - minimum_weight = 44
Range is essential in data analysis as it gives a quick sense of variability in the data set, however it vulnerable to outliers since it gives importance to the maximum and minimum values even if they are extreme.
Interquartile Range(IQR) is the difference between the first quartile (Q1) and third quartile(Q3) value. First Quartile is the median of the lower half of the data while Thrid quartile is the median of the upper of the data set. Therefore
IQR = Q3 - Q1
Lets calculate the IQR of the vector weights step by step;-
- Define the data weights and arrange the data in ascending order.
weights = 52, 52, 55, 58, 63, 68, 71, 76, 85, 96. - Determine the first quartile (Q1). Select the lower half(first five values) of the data and find their median which is the first quartile (Q1)
lower_half = 52, 52, 55, 58, 63
Q1 = 55
- Determine the third quartile (Q3). Select the upper half(last five values) and find their median which is the third quartile.
upper_half = 68, 71, 76, 85, 96
Q3 = 76
- Calculate the Interquartile Range (IQR) by finding the difference between Q1 and Q3.
IQR = Q3 - Q1 = 76 - 55 = 21
The IQR for the weights data set is 21.
Range and IQR can be calculated in R environment using the range() and IQR() function respectively. However function range returns the maximum and the minmum values in the dataset.
# Sample vector
athlete_weights = c(55, 76, 52, 68, 71, 63, 58, 52, 85, 96)
# RANGE
range(athlete_weights) # returns maximum and minimum values## [1] 52 96## [1] 44# INTER QUARTILE RANGE (IQR)http://127.0.0.1:38237/rmd_output/1/basic-data-types-and-structures.html
IQR(athlete_weights)## [1] 19Practical exercise
Load the iris data set and calculate the range and the Interquartile Range for the Petal Length and petal width for each iris species
7.1.2 Visualization of Descriptive Statistics
- Boxplots
Boxplots provide a visual summary of data distribution. It helps the analyst understand the spread, skewness and outliers in the data set.
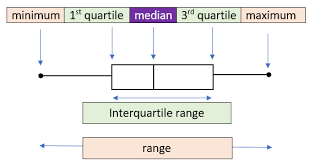
The diagram above shows a labelled boxplot. Lets breakdown each part;
- Minimum(Lower Whisker): is the smallest data point that appear between the first quartile(Q1) and 1.5x Interquartile Range(IQR) towards the lower limit(left side here.
- Maximum(Upper Whisker: is the largest data point that appear between the third quartile(Q3) and 1.5x IQR towards the upper limit(right side here)
- First Quartile(Q1): is the 25\(^{th}\) percentile depicting that 25% of the data points are below here.
- Third Quartile(Q3): is the 75\(^{th}\) percentile, depicting that 75% of the data points are above here.
- Median(Q2): is the 50\(^{th}\) percentile that divides the data into two equal halves, 50% of the data points are above and below here.
- Interquartile Range: The difference between the third quartile(Q3) and the first quartile(Q1).
- Outliers: Data points that fall outside the whiskers are considered as outliers and are plotted as dot alone.
Lets engage in a practical session and plot a boxplot from the ggplot.
library(ggplot2)
# Sample data
set.seed(123) # for reproducibility
df <- data.frame(
group = rep(c("A", "B", "C"), each = 50),
value = c(rnorm(50, mean = 10, sd = 2),
rnorm(50, mean = 15, sd = 2.5),
rnorm(50, mean = 20, sd = 3))
)
# Create some outliers
outliers <- data.frame(
group = c(rep("A", 4), rep("B", 4), rep("C", 4)),
value = c(-2, 3, -30, -35, 50, 6, 45, 50, -17, 8, 60, 65) # Low and high outliers
)
# Introduce the outliers into the data set
df_with_outliers <- rbind(df, outliers)
# Plot a simple boxplot
ggplot(df_with_outliers, aes(x = value)) +
geom_boxplot(outlier.colour = "red") +
labs(
title = "Boxplot of Values",
x = "Value"
) +
theme_minimal()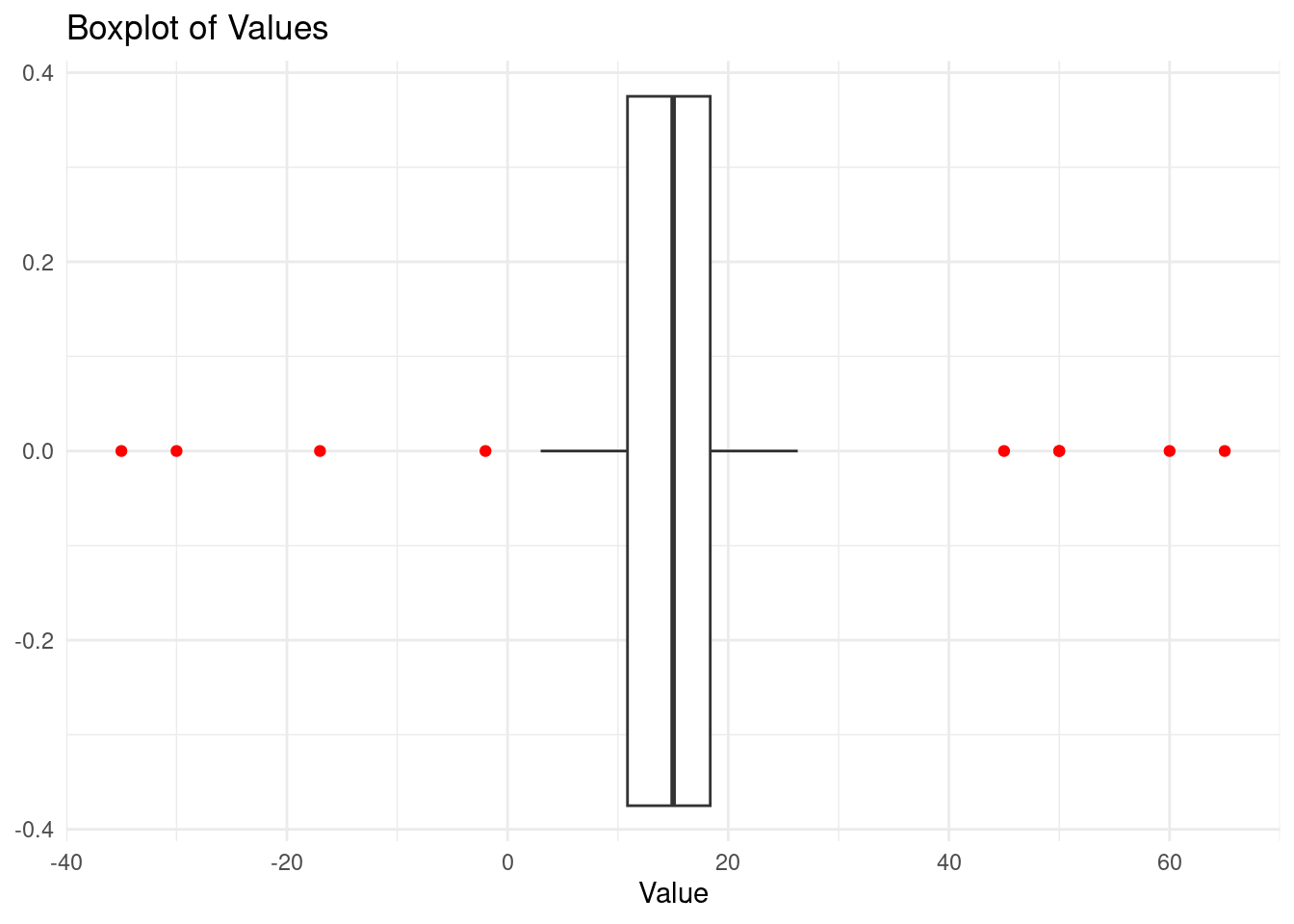
The red dots are the outliers
Practical exercise
Use the iris data set to plot boxplots that represent the petal length for each species. Analyze the boxplots and compare them.
- Histograms and Density Plots
These two types of plots are used to visualize the distribution of data.
A histogram is a graphical representation of the distribution of a data set. It divides the data into bins (intervals) and displays the frequency (or count) of data points that fall within each bin. Histograms are particularly useful for:
- Visualizing the shape of the data distribution: Whether the data is skewed, symmetric, or multimodal.
- Identifying outliers: Extreme values that fall far outside the range of most data points.
- Understanding the spread: How data points are distributed across the range of values.
Lets plot a simple histogram for this;
# Simple Histogram
ggplot(df_with_outliers, aes(x = value)) +
geom_histogram(binwidth = 5, fill = "skyblue", color = "black") +
labs(
title = "Histogram of Values with Outliers",
x = "Value",
y = "Frequency"
) +
theme_minimal()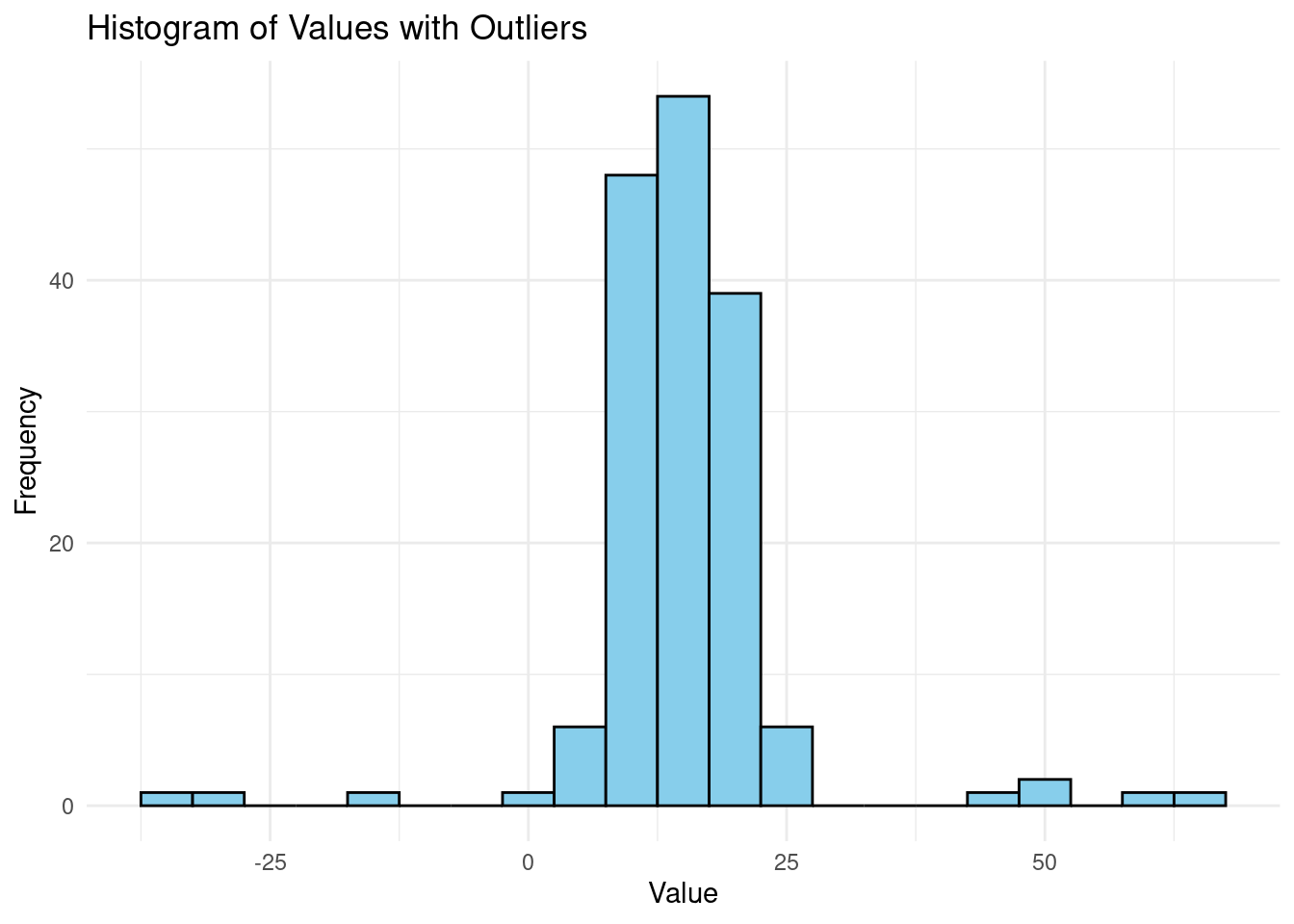 Most values in the data set range between 10 and 20. Let,s also plot the data for a nomal distribution.
Most values in the data set range between 10 and 20. Let,s also plot the data for a nomal distribution.
ggplot(df, aes(x = value)) +
geom_histogram(binwidth = 5, fill = "skyblue", color = "black") +
labs(
title = "Histogram of Values",
x = "Value",
y = "Frequency"
) +
theme_minimal()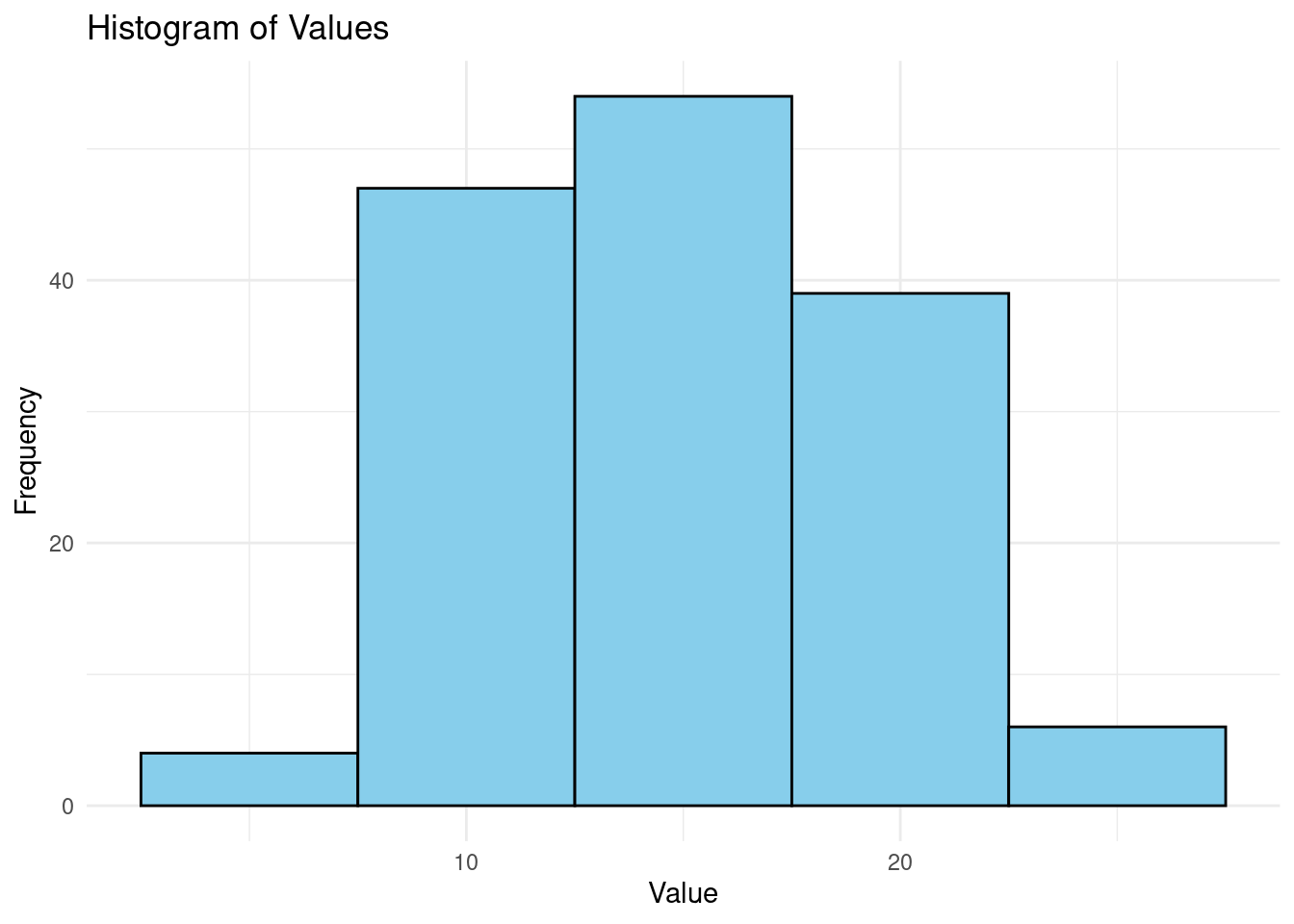
Most of the values are at the center and make a bell-curve.
On the other hand, a density plot is a smoothed version of a histogram. It estimates the probability density function of a continuous variable, allowing for a smoother visualization of the distribution. Density plots are particularly useful for:
- Comparing distributions: Since density plots can overlay multiple distributions, they are helpful in comparing different data sets or groups within a data set.
- Visualizing the shape of the data: The smooth curve makes it easier to identify peaks (modes), skewness, and the overall spread.
- Understanding the relative likelihood of data: The area under the density curve represents the probability of data falling within a particular range.
Lets plot a density plot and find the visual difference;
# Create a density plot
ggplot(df, aes(x = value)) +
geom_density(fill = "lightgreen", color = "darkgreen", alpha = 0.6) +
labs(
title = "Density Plot of Values",
x = "Value",
y = "Density"
) +
theme_minimal()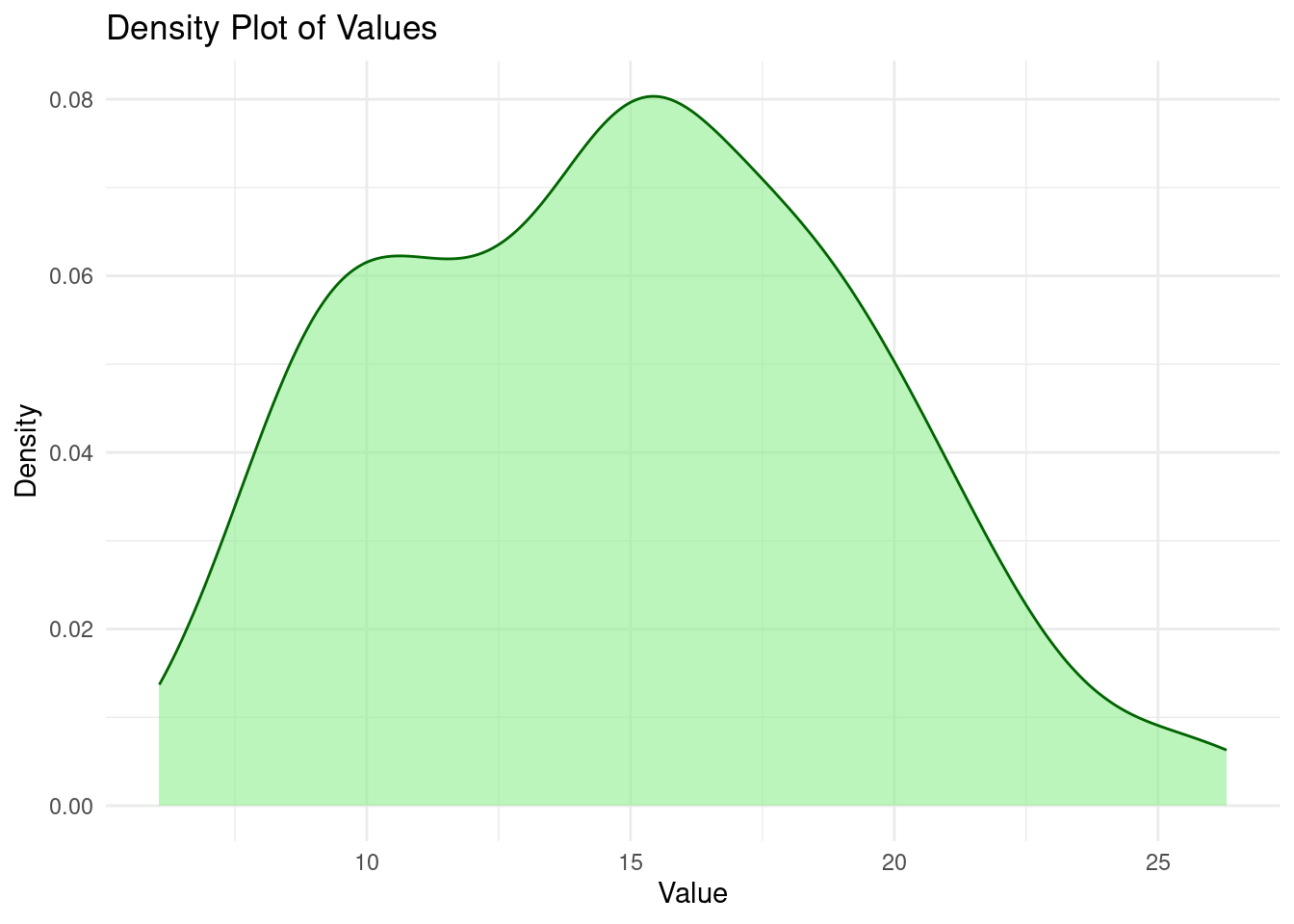
From the graphs above, histograms provide a bar-chart-like representation of the data distribution while density plots proved a smoother view of the data distribution.
Practical exercise
Load the airquality, an inbuilt R data set. Plot a density plot and histogram separately to visualize the distribution of the speed of wind in mph(Wind)
7.1.3 Hands On Exercise
In this exercise you will use the "Pima.te" data set from the MASS package. Follow the steps below to get the data ready and started;
- Install the
MASSpackage by;
install.packages("MASS")- Import the library
library(MASS)- Load the pima dataset
# Load the data set
data("Pima.te")
# Show the first few rows of the data
head(Pima.te)After getting the data ready, apply the skills learnt to;
- Calculate the destcriptive statistics (mean, mode and median etc)
- Find the relationship between the plasma glucose concentration in an oral glucose tolerance test(
glu) and the diastolic blood pressure(bp) using a scatter plot - Compare the average age of the patients that had diabetes(’type`) using a bar chart
- Find the distribution of age of the patients using a histogram. Explain the distribution.
7.2 Correlation and Regression Analysis
7.2.1 Introduction to Correlation
- Pearson and Spearman Correlation
Correlation is the relationship between two variables. It can also defined to as the statistic measure to the degree to which two variables move in relation to each other.
There are two types of correlation in statistics;- pearson and spearman correlations. They differ in their calculation methods, assumptions and type of relationships they are suited for.
Pearson correlation measures the linear relationship between two variables with the assumptions that there is a linear relationship between the variables and the data is normally distributed. Contrarily, Spearman correlation measures the monotonic relationship(whether there is a consistent positive or negative change ) between two variables. The data to be analyzed, don’t need to be normally distributed, it can be ordinal with the variables having a non-linear relationship.
Lets take two variables, X and Y, Pearson correlation is calculated by dividing the covariance of X and Y with their product of standard deviation. Below is its formula;
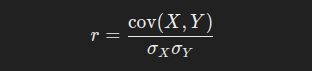
r is the pearson correlation and it can range from -1 to +1.
Spearman correlation is calculated by ranking data points, then applying Pearson correlation formula. Below is the formula of spearman correlation;
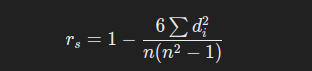
where;
dis the difference between the ranks of corresponding variablesnis the number of observationsris the pearson correlation
Spearman correlation is insensitive with outliers because it uses ranks other than outliers.
Practical exercise
Load the airquality data set. Calculate the correlation of Wind and temperature Wind. Interpret the coefficients for various data sets.
- Visualizing Correlation
The relationship of exactly two numeric continuous variables can be viewed using scatter plots while the relationship between multiple(two or more) can be analyzed using a correlation plot(heatmap)
# Set seed for reproducibility
set.seed(123)
# Create a linear relationship with some noise
x <- rnorm(100, mean = 50, sd = 10)
y <- 2 * x + 5 + rnorm(100, mean = 0, sd = 5) # Linear relationship with noise
# Combine into a data frame
df <- data.frame(x = x, y = y)
# Create a scatter plot
ggplot(df, aes(x = x, y = y)) +
geom_point(color = "blue") +
labs(
title = "Scatter Plot of X vs Y",
x = "X Variable",
y = "Y Variable"
) +
theme_minimal()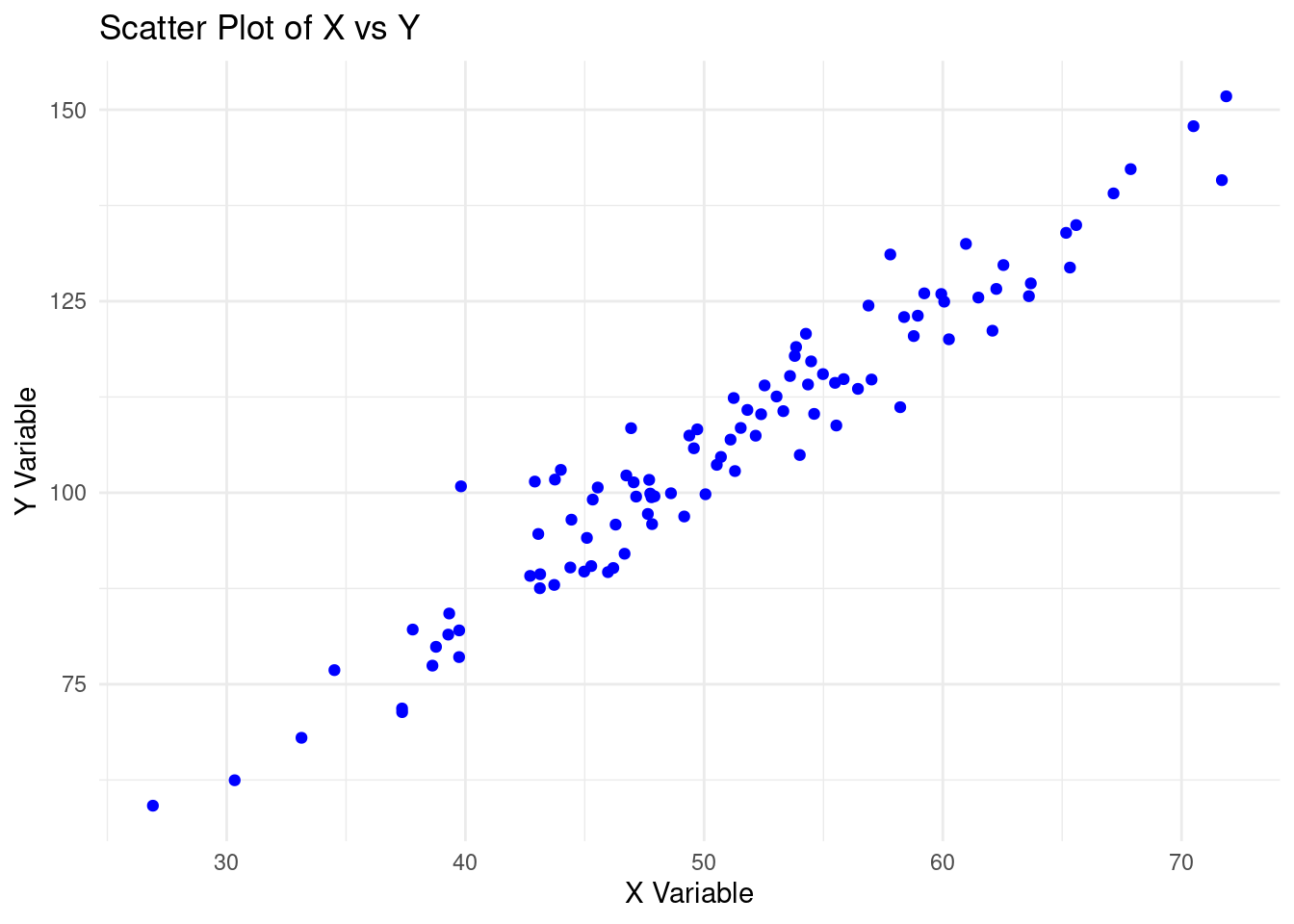
In the scatter plot above;
- The
Xandyvariables have a positive correlation. The increase inXleads to an increase inY. - There are no outliers in the data set. There are no data points that are out of the general pattern.
- The relationship between
XandYis linear.
On the other hand, the heatmap is a visual representation of the correlation matrix where each cell represents the relationship between two variables. The color of the cell indicates the strength of the relationship between the concerned variables.
Lets create a data frame with multiple variables, and plot a heatmap.
# Set seed for reproducibility
set.seed(123)
# Create 6 variables
var1 <- rnorm(100, mean = 50, sd = 10)
var2 <- rnorm(100, mean = 60, sd = 15)
var3 <- rnorm(100, mean = 70, sd = 20)
var4 <- rnorm(100, mean = 80, sd = 25)
var5 <- 3 * var1 + 7 + rnorm(100, mean = 0, sd = 5) # Linear relationship with var1
var6 <- rnorm(100, mean = 90, sd = 30)
# Combine into a data frame
df <- data.frame(var1 = var1, var2 = var2, var3 = var3, var4 = var4, var5 = var5, var6 = var6)
# Display the first few rows of the data set
head(df)## var1 var2 var3 var4 var5 var6
## 1 44.39524 49.34390 113.97621 62.11895 139.8180 71.94321
## 2 47.69823 63.85326 96.24826 61.18278 144.2514 60.18904
## 3 65.58708 56.29962 64.69710 56.53653 200.5875 120.80355
## 4 50.70508 54.78686 80.86388 53.68717 158.9710 112.53184
## 5 51.29288 45.72572 61.71320 69.07101 164.2321 44.72500
## 6 67.15065 59.32458 60.47506 88.27948 200.1992 87.14558var5 has a linear relationship with var1. Lets plot a heatmap of the data frame df. However, lets install the ggcorrplot and the corrplot packages
install.packages(c("ggcorrplot", "corrplot"))Create a correlation heatmap using the ggcorrplot package
library(ggcorrplot)
# Calculate the correlation matrix
cor_matrix <- cor(df)
# Create a correlation heatmap
ggcorrplot(cor_matrix, method = "circle", lab = TRUE, lab_size = 3, colors = c("red", "white", "blue")) +
labs(title = "Heatmap 1")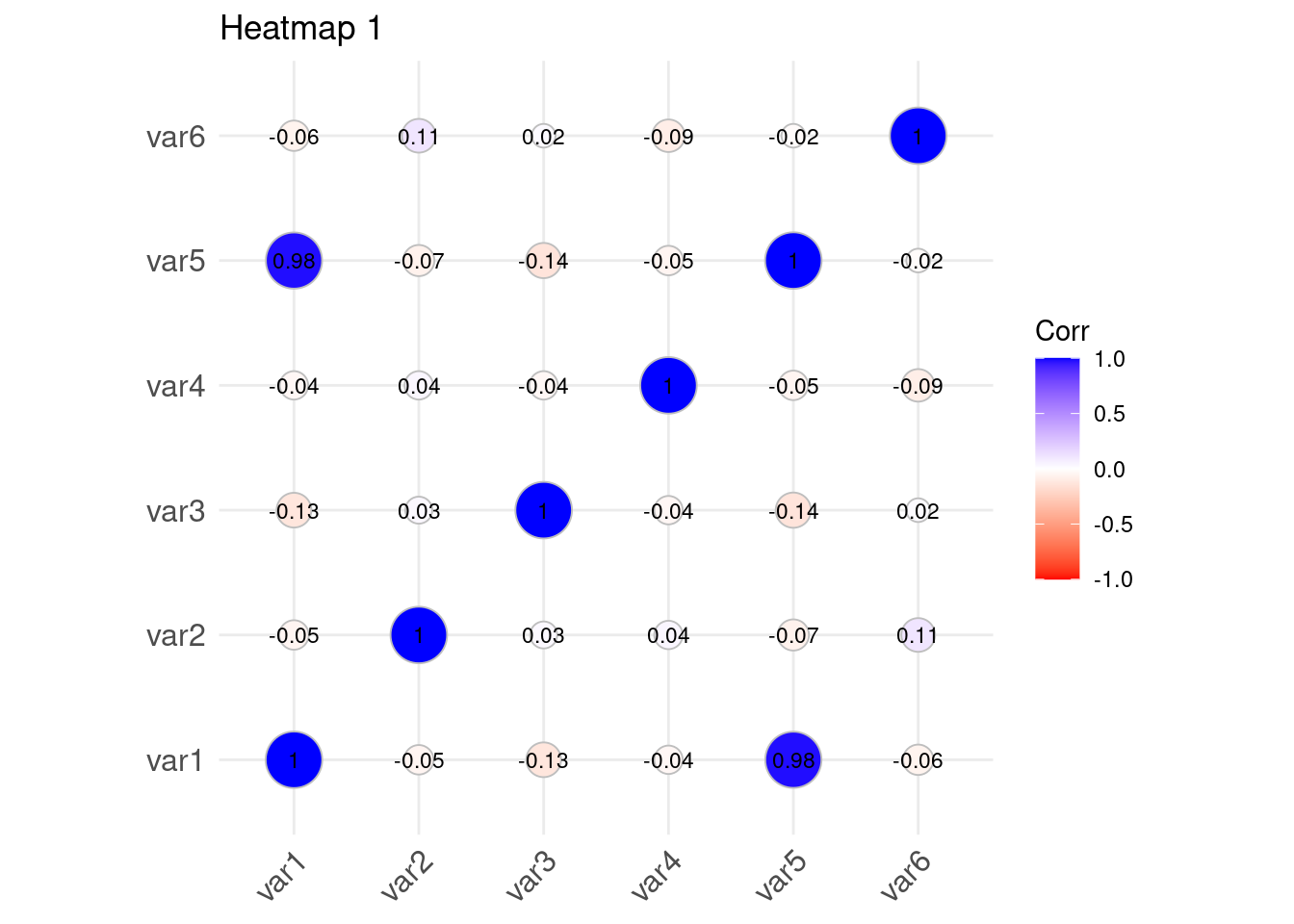
Lets repeat the same using the corrplot package
## corrplot 0.94 loaded# Create a correlation heatmap using corrplot
corrplot(cor_matrix, method = "color", type = "upper", tl.col = "black", tl.srt = 45)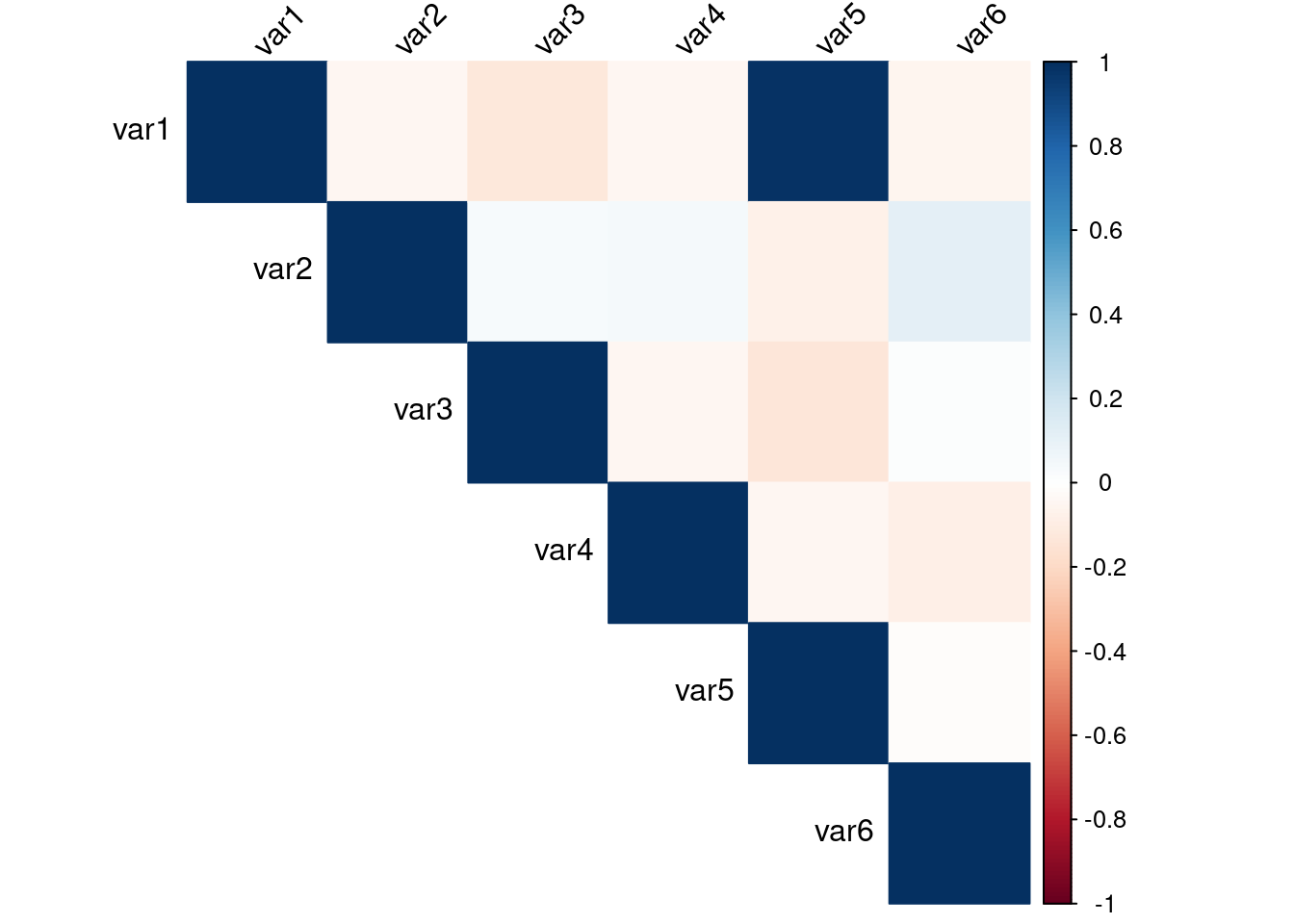
The two plots visualizes the correlation between the variables in the data set. Var5 and Var1 have a high correlation(0.98) while Var5 and Var2 have a very low correlation value(-0.07)
Practical exercise
Load the same airquality inbuilt R data set. Create a scatter plot to show the relationship between Wind and Temp variable. Also plot a correlation heatmap for numeric data set(Ozone, Solar.R, Wind and Temp)
7.2.2 Introduction to Regression Analysis
Regression is a statistical method used to measure the strength and relationship of a target(dependent) with one or more independent variables. Correlation is very vital in determining regression. Linear regression is the most technique of regression, there are some more advanced forms of regression.
- Simple Linear Regression
This type of regression is used to estimate the relation of one independent variable with the target variable. For instance the relationship between age and height of children. relationship between weight and BMI of athletes, relationship between rainfall and soil erosion.
When creating a simple linear regression model, a line is fitted a line to the observed data.
Simple linear regression is modeled by this equation;
y = c + BX + eWhere;-
yis the target variableXis the independent variableBis the slope.gradient(change inyfor one-unit change inX)cis the y-intercept(Value of target variable when independent variable is zero)eis the error/noise. variation inybut not as a resultant explained byX
The goal of simple of linear regression it to have the best fitting line that with the equation y = BX + c. Base R has a method of fitting a linear regression and finding the best fit line using lm() function. lm() stands for “linear model”.
Lets create a simple linear regression model to a hypothetical data set where height of athletes is predicted based on weight.
# Create a sample dataset
height <- c(150, 160, 170, 180, 190) # Independent variable (x)
weight <- c(65, 70, 75, 80, 85) # Dependent variable (y)
# Combine into a data frame
data <- data.frame(height, weight)
print(data)## height weight
## 1 150 65
## 2 160 70
## 3 170 75
## 4 180 80
## 5 190 85# Fit the linear model
lin_reg <- lm(weight ~ height, data = data)
# View the summary of the model
summary(lin_reg)## Warning in summary.lm(lin_reg): essentially perfect fit: summary may be
## unreliable##
## Call:
## lm(formula = weight ~ height, data = data)
##
## Residuals:
## 1 2 3 4 5
## 1.335e-14 -1.367e-14 -6.097e-15 -1.891e-16 6.607e-15
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.000e+01 6.575e-14 -1.521e+14 <2e-16 ***
## height 5.000e-01 3.854e-16 1.297e+15 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.219e-14 on 3 degrees of freedom
## Multiple R-squared: 1, Adjusted R-squared: 1
## F-statistic: 1.683e+30 on 1 and 3 DF, p-value: < 2.2e-16Coefficients, the value B and c represent the intercept and the gradient(slope) in the equation. The R- Squared value indicates how well the independent variable explains the dependent variable. The closer the R-square value to 1 the better the fit. Finally, the p-value is associated with the gradient and tells the statistician whether the relationship between the variables is statistically significant.
Practical exercise
Using the airquality data set fit a linear regression model to find the relationship between Wind (independent variable) and Temp (dependent/target variable)
- Multiple Linear Regression
Unlike simple linear regression, multiple linear regression describes the linear relationship between two or more independent variables with one target(dependent) variable. The objective of multiple linear regression is to;-
- Find the strength of the relationship between two or more independent variables with the target variables.
- Find the value of the target variable at a certain value of the independent variable.
When working on a multiple linear regression it is assumed that; the variance is homogeneous such that the prediction error does not change significantly across the predictor(independent) variables. It is also assumed, observations were independent and there was no hidden relationships among the variables when collecting the data. Additionally, the collected data follows a normal distribution and the independent variables have a linear relationship(linearity) with the dependent variable, therefore, the line of best fit through the data points is straight and not curved.
Multiple linear regression is modeled by;-

where;-
- \(y\) is the predicted value of the target variable.
- \(\beta_0\) is the y-intercept. Value of y when all other parameters are zero.
- \(\beta_1X_1\): \(\beta_1\) is the regression coefficient of the first independent variable while \(X_1\) is the independent variable value. \(\cdots\) do the same for however the number of independent variables are present.
- \(\beta_nX_n\): the regression coefficient of the last independent variable.
- \(\epsilon\) is the model error(variation not explained by the independent variables)
The Multiple linear regression model calculates three things to find the best fit line for each independent variable;-
- The regression coefficient \(\beta_iX_i\) that will minimize the overall error rate(model error).
- The associated p-value. If the relationship between the independent variable is statistically significant.
- The t-statistic of the model. T-statistic is the ratio of the difference in a number’s estimated value from its assumed value to its standard error.
Lets create a multiple linear regression from a hypothetical data using base R.
# Create a sample dataset
height <- c(150, 160, 170, 180, 190) # Independent variable 1 (x1)
age <- c(25, 30, 35, 40, 45) # Independent variable 2 (x2)
weight <- c(65, 70, 75, 80, 85) # Dependent variable (y)
# Combine into a data frame
data <- data.frame(height, age, weight)
data## height age weight
## 1 150 25 65
## 2 160 30 70
## 3 170 35 75
## 4 180 40 80
## 5 190 45 85# Fit the linear model with multiple predictors
model <- lm(weight ~ height + age, data = data)
# View the summary of the model
summary(model)## Warning in summary.lm(model): essentially perfect fit: summary may be
## unreliable##
## Call:
## lm(formula = weight ~ height + age, data = data)
##
## Residuals:
## 1 2 3 4 5
## 1.335e-14 -1.367e-14 -6.097e-15 -1.891e-16 6.607e-15
##
## Coefficients: (1 not defined because of singularities)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.000e+01 6.575e-14 -1.521e+14 <2e-16 ***
## height 5.000e-01 3.854e-16 1.297e+15 <2e-16 ***
## age NA NA NA NA
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.219e-14 on 3 degrees of freedom
## Multiple R-squared: 1, Adjusted R-squared: 1
## F-statistic: 1.683e+30 on 1 and 3 DF, p-value: < 2.2e-16Practical exercise
Using the airquality data set, fit a multiple linear regression model whereby the Solar radiation(Solar.R), Ozone and Wind are the independent variables while the Temperature (Temp) is the dependent variable. Interpret and analyze the results
7.2.3 Hands-on Exercises
In this course, you will be required to download the Boston Housing data set from here. Fit a multiple regression model to the data set. The goal is to predict the price of the houses in Boston, the MEDV variable. Interpret and discuss the multiple linear regression model and its implication
7.3 Advanced Statistical Methods
7.3.1 Introduction to Hypothesis Testing
7.3.1.1 Concept of Hypothesis Testing
Hypothesis testing is a type of statistical analysis that is used to make assumptions of a population based on a sample of data. It is particularly used to find the relationship between two variables(populations). A real life example of hypothesis testing is that a teacher may assume that 60% of the students come from a middle-class family. There are two types of hypothesis;
- Null hypothesis(\(H_0\))
- Alternate hypothesis (\(H_1\) or \(H_a\))
Null hypothesis is states that there is no effect or no difference(\(\mu = 0\)). For instance there is no effect of standards of living to college admissions. Alternate hypothesis is the opposite and contradicts the null hypothesis. It provide evidence for what the statistician is trying to find(\(\mu \neq 0\)). In this case, the standards of living have an effect on college admissions.
The important aspects before conducting hypothesis testing are;-
- Significance level. It is the probability of rejecting the null hypothesis when it is actually true.
- P-Value is the probability of obtaining a test statistic at least as extreme as the one observed, given the null hypothesis is true. Most hypothesis testing projects are set at 0.05. Less than 0.05(or the set value) indicates the null the test is statistically significant and the null hypothesis should be rejected. Otherwise, the test is statistically insignificant and the null hypothesis is not rejected.
- Test statistic also called T-statistic is a standardized value calcluated during a hypothesis test. It cab z-test or a t-test. -Decision rule is based on the calculated p-value and the significant level. In a hypothesis test where the significant and the p-value is 0.03444 the null hypothesis is not rejected.
Now that you are familiar with the hypothesis testing aspects, take the following steps to perform hypothesis testing;-
- Formulating the hypothesis by defining the null and alternate hypothesis.
- Collect and analyze the data.
- Choose a significant level(\(a\)) and calculate the p-value.
- Make a decision by comparing the p-value to the significant level.
- Conclude your analysis results.
7.3.1.2 T-tests
- One-Sample t-test
One sample t-test is a statistical method used to find if the mean of a sample is different from the population(or preassumed) mean.
It is based on the t-distribution(most observations fall close to the mean, and the rest of the observations make up the tails on either side) and is commonly used when dealing with small sample sizes. One sample t-test is especially performed where the population standard deviation is unknown.
Below is the formula for one sample t-test \[t={{\overline{X}-\mu}\over s / \sqrt{n}}\]
where;
- \(t\): the one sample t-test value. t-test statistic
- \(n\): the number of the observations in the sample
- \(\overline{X}\): is the sample mean
- \(s\): standard deviation of the sample
- \(\mu\): Hypothesized population mean
The result \(t\), simply measures how many standard errors the sample mean is away from the hypothesized population mean.
Before conducting t-test, there is a need to establish the null(H0) and alternate hypothesis(Ha) where;
- Null Hypothesis(H0): There is no significant difference between the sample mean and the population(hypothesized) mean.
- ALternate Hypothesis(Ha): There is a significant difference between the sample mean and the population mean.
P-value is the probability value that tells you how likely is that your data could have occurred under null hypothesis. In our case a p-value of below 0.05 is considered to be statistically significant and the null value is rejected. The vice versa is true
Lets perform a t-test using R;
We will generate sample data
# Set seed for reproducibility
set.seed(123)
# Generate random student marks (out of 100)
student_marks <- rnorm(30, mean = 65, sd = 10)
# Display the first few marks
head(student_marks)## [1] 59.39524 62.69823 80.58708 65.70508 66.29288 82.15065Perform the t-test
# Conduct one-sample t-test
t_test_result <- t.test(student_marks, mu = 70)
# Display the t-test result
print(t_test_result)##
## One Sample t-test
##
## data: student_marks
## t = -3.0546, df = 29, p-value = 0.004797
## alternative hypothesis: true mean is not equal to 70
## 95 percent confidence interval:
## 60.86573 68.19219
## sample estimates:
## mean of x
## 64.52896Practical exercise
Conduct one sample t-test on the sepal length of the setosa iris. The pre-assumed mean is 5.84 units.
- Two-Sample t-test
Unlike one sample t-test where a sample population is tested against a pre-assumed mean, the Tow-sample t-test determines if there is a significant difference between the means of two independent populations.
The practical application of two-sample t-test can be when comparing the test scores of two classes. This helps the statistician to understand if one class did better than the other one or it’s just a matter of luck.
These are the prerequisites before conducting a two-sample t-test;
- The groups contain separate data with a similar distribution.
- The two populations have a normal(typical bell-curve) distribution.
- The two sample populations have a similar variations
The two sample t-test is calculated by;
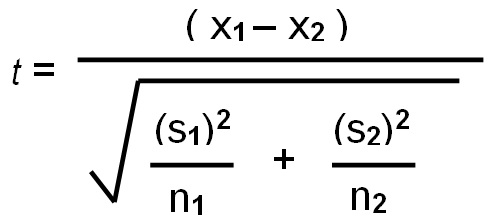
Where;
- \(\overline{x}_1\) and \(\overline{x}_2\) are the mean of the first sample and the second sample respectively
- \(s_{1}\) and \(s_{2}\) are the standard deviation of sample 1 and sample 2 respectively
- \(n_1\) and \(n_2\) are the sample sizes of the first and second sample respectively.
Let create a random population of student scores for two classes and perform two-sample t-test in R;
# Generate the population sample
set.seed(123)
group_A_scores <- rnorm(25, mean = 75, sd = 8) # Group A
group_B_scores <- rnorm(25, mean = 80, sd = 10) # Group B
# Display the first few scores of each group
head(group_A_scores)## [1] 70.51619 73.15858 87.46967 75.56407 76.03430 88.72052## [1] 63.13307 88.37787 81.53373 68.61863 92.53815 84.26464Performing the two sample t-test. Lets set the confidence level to 95%(0.95)
ttest_result = t.test(group_A_scores, group_B_scores,
alternative = "two.sided", mu = 0, paired = FALSE,
var.equal = FALSE, conf.level = 0.95)
ttest_result##
## Welch Two Sample t-test
##
## data: group_A_scores and group_B_scores
## t = -2.6403, df = 46.312, p-value = 0.01125
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -11.080984 -1.495049
## sample estimates:
## mean of x mean of y
## 74.73336 81.02137- t-value = -2.6403: This indicates the difference between the means of the two groups, in terms of standard errors. A higher absolute value suggests a larger difference.
- Degrees of freedom (df) = 46.312: This reflects the sample size and variability in the data.
- p-value = 0.01125: Since the p-value is less than 0.05, we reject the null hypothesis. This suggests that the difference in means between Group A and Group B is statistically significant.
- 95% confidence interval: (-11.08, -1.50): This indicates that we are 95% confident that the true difference in means lies between -11.08 and -1.50.
- Mean of x (Group A) = 74.73, Mean of y (Group B) = 81.02: The average score of Group B is higher than Group A.
In summary, the test shows a significant difference between the means of the two groups, with Group B having higher scores
Practical exercise
Using the iris data set, compare the petal length of the versicolor and virginica species using two-sample t-test. Interpret the results
7.3.1.3 ANOVA (Analysis of Variance)
ANOVA is a statistical test used to analyze the difference between the means of more than two groups. This is different from the ttest that analyzes one or two groups, it uses F test to find the statistical significance. Multiple means are compared at once and if one mean is different the hypothesis is rejected.
The F test compares the variance in each group from the overal group variance.
An practical example of ANOVA is where a farmer wants to test the effect of three different fertilizers on the crop yield. The difference in the crop yield will be calculated.
Before conducting ANOVA, the following assumptions are made;
- Independence of observations: the data was collected using statistically valid sampling methods and there are no hidden relationships among the observations.
- Normal distribution: the dependent variable should follow a normal distribution.
- Homogeinity of variance: All the groups being tested should have similar variations.
Lets calculate the ANOVA using the the crop yield data set. The fertilizer are in three categories; 1, 2 and 3
# Load the data set
crop_df <- read.csv("data/cropdata.csv")
head(crop_df) # view the first few rows of the data set## density block fertilizer yield
## 1 1 1 1 177.2287
## 2 2 2 1 177.5500
## 3 1 3 1 176.4085
## 4 2 4 1 177.7036
## 5 1 1 1 177.1255
## 6 2 2 1 176.7783## Call:
## aov(formula = yield ~ fertilizer, data = crop_df)
##
## Terms:
## fertilizer Residuals
## Sum of Squares 5.74322 36.21101
## Deg. of Freedom 1 94
##
## Residual standard error: 0.6206638
## Estimated effects may be unbalancedThe ANOVA output provides insights into the variation in crop yield explained by the fertilizer type. Here’s a detailed breakdown of the results:
Sum of Squares (fertilizer) = 5.74322: This value represents the variation in crop yield that can be attributed to the different types of fertilizers used in the experiment. In this case, 5.74322 units of the total variation are explained by fertilizer differences.
Sum of Squares (Residuals) = 36.21101: This is the unexplained variation in crop yield, also known as the error term. This shows how much of the variation is due to factors not accounted for in the model, such as environmental factors or random error.
Degrees of Freedom (fertilizer) = 1: There is only 1 degree of freedom for the fertilizer factor, which means there was a comparison between two groups (likely two fertilizer types or one fertilizer versus a control).
Degrees of Freedom (Residuals) = 94: There are 94 degrees of freedom associated with the residuals. This is related to the total number of observations minus the number of groups being compared. In this case, the large degrees of freedom indicate a sizable data set.
Residual Standard Error = 0.6206638: This value represents the typical deviation of the observed yield values from the predicted values, given the current model. A lower residual standard error suggests a better fit of the model to the data, though this value needs to be interpreted in context.
The results show that the fertilizer type explains some of the variation in crop yield (Sum of Squares = 5.74322), while a larger portion remains unexplained (Sum of Squares of Residuals = 36.21101). To fully interpret the significance of this effect, a p-value and F-statistic would typically be calculated, but these are not provided here. Additionally, the residual standard error (0.6206638) gives an indication of the spread of the data around the predicted values, but more information would be needed to assess the strength of the model’s fit.
In conclusion, while the fertilizer has some effect on crop yield, the overall variability and potential unbalanced data need further exploration for a complete understanding.
Practical exercise
Perform ANOVA on the sepal width of the three species in the iris data set and interpret the results.
7.3.1.4 Chi-Square Test
This is a statistical test that determines the difference between the observed and the expected data. It determines if the relationship between two categorical variables is due to chance or a relationship between them.
It is calculated by; \[x_{c}^{2} = \frac{\sum(O_{i}-E_{i})}{E_i}\]
Where;
- \(c\) is the degree of freedom. This is a statistical calculation that represents the number of variables that can carry and is calculated to ensure the chi-square tests are statistically valid
- \(O\) is the observed value
- \(E\) is the expected value
Lets perform Chi-square on a survey data from the MASS library. The survey data represents data from a survey conducted on students.
- Null Hypothesis (\(H_0\)): The smoking habit is independent of the student’s exercise level
- ALternate Hypothesis (\(H_a\)): The smoking habit is dependent on the exercise level.
Load the data
##
## Attaching package: 'MASS'## The following object is masked from 'package:patchwork':
##
## area## The following object is masked from 'package:dplyr':
##
## select## Sex Wr.Hnd NW.Hnd W.Hnd Fold Pulse Clap Exer Smoke Height M.I
## 1 Female 18.5 18.0 Right R on L 92 Left Some Never 173.00 Metric
## 2 Male 19.5 20.5 Left R on L 104 Left None Regul 177.80 Imperial
## 3 Male 18.0 13.3 Right L on R 87 Neither None Occas NA <NA>
## 4 Male 18.8 18.9 Right R on L NA Neither None Never 160.00 Metric
## 5 Male 20.0 20.0 Right Neither 35 Right Some Never 165.00 Metric
## 6 Female 18.0 17.7 Right L on R 64 Right Some Never 172.72 Imperial
## Age
## 1 18.250
## 2 17.583
## 3 16.917
## 4 20.333
## 5 23.667
## 6 21.000Create a contigency table between the Smoke and the Exercise leel.
# Create a contingency table with the needed variables.
stu_data = table(survey$Smoke,survey$Exer)
print(stu_data)##
## Freq None Some
## Heavy 7 1 3
## Never 87 18 84
## Occas 12 3 4
## Regul 9 1 7Perform the chi-square test on the stu_data, the contigency table.
##
## Pearson's Chi-squared test
##
## data: stu_data
## X-squared = 5.4885, df = 6, p-value = 0.4828From the results, the p-value is 0.4828 which is greater than 0.05 therefore the null hypothesis is not rejected. It’c concluded that the smoking habit is independent of the exercise level since there is weak to now correlation between the Smoke and Exer variables.
Finally, lets visualize the results from the contigency table;
# Visualize the data with a bar plot
barplot(stu_data, beside = TRUE, col = c("lightblue", "lightgreen"),
main = "Smoking Habits vs Exercise Levels",
xlab = "Exercise Level", ylab = "Number of Students")
# Add legend separately
legend("center", legend = rownames(stu_data), fill = c("lightblue", "lightgreen"))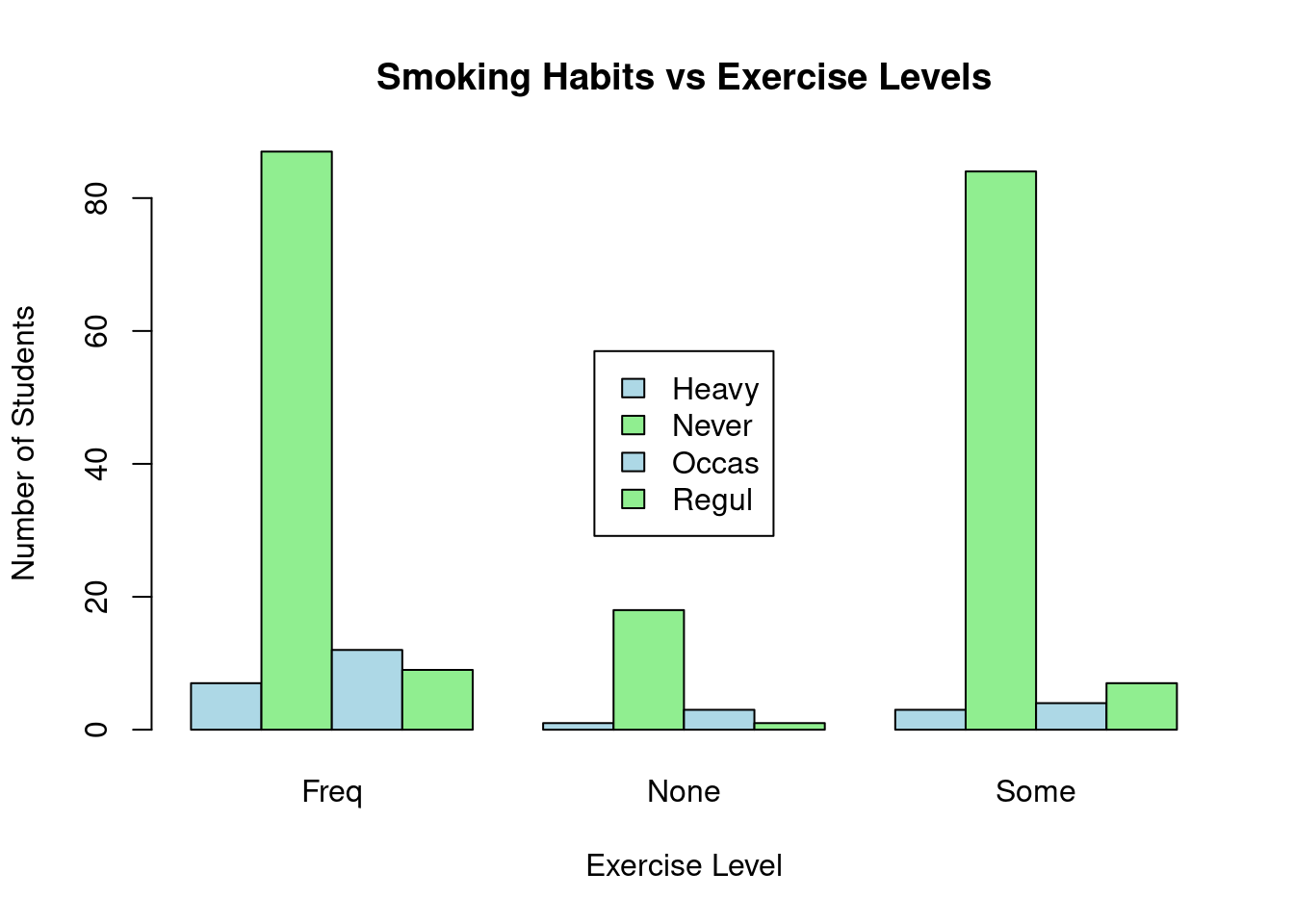
You can see from the table, those students who never smoke lead in every exercise level while the heavy smokers are the least in every group.
Practical exercise
Using the Iris dataset, perform a Chi-square test to determine if there is a relationship between two categorical variables: the species (Species) and a new categorical variable that classifies sepal width (Sepal.Width) into categories (e.g., “Short”, “Medium”, “Long”).
- “Short”: below 3.0
- “Medium”: above 3.0 to 3.8
- “Long”: above 3.8
Follow the steps below;
- Create a new variable
sepal.Width.Categoryin the data set by categorizing theSepal.Widthvariable into 3 categories:"Short","Medium", and"Long"(as per the defined ranges). - Perform a Chi-square test to see if there’s an association between the new
sepal.Width.Categorycategories and theSpeciescolumn. - Interpret the results of the Chi-square test
7.3.2 Hands-on Exercises
You are required to download the Groundhog Day Forecasts and Temperatures data set from here.
- Perform one sample t-test on February Average temperature. The pre-assumed mean is 35
- Conduct two sample t-test between the North East average temperature for March and the overall March daily temperature
- Perform ANOVA between the presence of Punxsutawney Phil and the February average temperature
Interpret the results
7.4 Project: Applying Statistical Analysis
7.4.1 Project Overview
The primary goal of this project is to give you an opportunity to apply and integrate all the statistical concepts techniques learned so far using R. The project will guide you through the complete statistical modeling workflow.
You are therefore required to choose a data set from the list below;
- MBA Admission dataset, Class 2025 - download here
- Global Black Money Transactions Dataset - download here
- Crop Yield Prediction Dataset - download here
- ChickWeight inbuilt R dataset - load from the command
data("ChickWeight") - Seatbelts data set - load from the command
data("Seatbelts") - The “Groceries” from the R package comes
arules- Load the data by first importing arules(library(arules)) then the data bydata("Groceries") "CreditCard"data from packageAER- Load the data by first importing AER (library(AER)) then the data bydata("CreditCard")
You will use the selected data set to;
- Identify the research questions that will help focus on what you want to investigate.
- Determine the key variables in your research questions like the independent and dependent variables.
- Formulate the null and alternate hypothesis
7.4.2 Conducting Statistical Analysis
You will use the statistical techniques learned for instance descriptive statistics, correlation, regression and hypothesis testing to analyze this data set
Note: Emphasize on interpreting the results and understanding their implications
7.4.3 Presenting Statistical Findings
You will finally prepare a brief presentation that will summarize the statistical analysis and research
Discuss in groups the insights obtained, challenges faced and any potential improvements
7.4.4 Example: Ecommerce Statistical Analysis
Load the data set
## CID TID Gender Age.Group Purchase.Date Product.Category
## 1 943146 5876328741 Female 25-45 30/08/2023 20:27:08 Electronics
## 2 180079 1018503182 Male 25-45 23/02/2024 09:33:46 Electronics
## 3 337580 3814082218 Other 60 and above 06/03/2022 09:09:50 Clothing
## 4 180333 1395204173 Other 60 and above 04/11/2020 04:41:57 Sports & Fitness
## 5 447553 8009390577 Male 18-25 31/05/2022 17:00:32 Sports & Fitness
## 6 200614 3994452858 Male 18-25 12/07/2021 15:10:27 Clothing
## Discount.Availed Discount.Name Discount.Amount..INR. Gross.Amount
## 1 Yes FESTIVE50 64.30 725.304
## 2 Yes SEASONALOFFER21 175.19 4638.992
## 3 Yes SEASONALOFFER21 211.54 1986.373
## 4 No 0.00 5695.613
## 5 Yes WELCOME5 439.92 2292.651
## 6 Yes FESTIVE50 127.01 3649.397
## Net.Amount Purchase.Method Location
## 1 661.004 Credit Card Ahmedabad
## 2 4463.802 Credit Card Bangalore
## 3 1774.833 Credit Card Delhi
## 4 5695.613 Debit Card Delhi
## 5 1852.731 Credit Card Delhi
## 6 3522.387 Credit Card Delhi7.4.4.1 Introduction
In this analysis, we aim to explore the Ecommerce data set and answer the following research questions:
- Are there significant differences in customer spending (Net Amount) based on gender or age group?
- Are discounts a significant factor in influencing purchasing decisions?
To address these questions, we formulate the following hypotheses:
- Hypothesis 1: There is no significant difference between the Net Amount spent by male and female customers.
- Hypothesis 2: The age group of customers does not affect the Net Amount spent.
- Hypothesis 3: There is no association between discount availed and the purchase method used.
7.4.4.2 T-Tests
7.4.4.2.1 One-Sample T-test
We conduct a one-sample t-test to determine if the average Gross Amount spent by customers differs significantly from a pre-defined industry standard of INR 5000.
- Null Hypothesis (\(H_0\)): The average Gross Amount is equal to INR 5000.
- Alternative Hypothesis (\(H_1\)): The average Gross Amount is not equal to INR 5000.
##
## One Sample t-test
##
## data: ecommerce$Gross.Amount
## t = -271.18, df = 54999, p-value < 2.2e-16
## alternative hypothesis: true mean is not equal to 5000
## 95 percent confidence interval:
## 2998.575 3027.298
## sample estimates:
## mean of x
## 3012.937The p-value is less than 0.05 therefore, there is enough evidence to reject the null hypothesis. The average gross amount is not equal to INR 5000
The average gross amount spent in a transaction is 3012.937, which is significantly different from the hypothesized value of 5000.
7.4.4.2.2 Two-sample T-Test
We use a two-sample t-test to assess whether there is a significant difference in the Net Amount spent between male and female customers.
- Null Hypothesis (\(H_0\)): There is no significant difference between male and female spending.
- Alternative Hypothesis (\(H_1\)): There is a significant difference between male and female spending.
library(dplyr)
# Gather male net amount
male_net_amount <- ecommerce %>%
filter(Gender=="Male") %>%
dplyr::select(Net.Amount)
# Gather female net amount
female_net_amount <- ecommerce %>%
filter(Gender=="Female") %>%
dplyr::select(Net.Amount)
# Perform ttest
t.test(male_net_amount, female_net_amount,
alternative = "two.sided", mu = 0, paired = FALSE,
var.equal = FALSE, conf.level = 0.95)##
## Welch Two Sample t-test
##
## data: male_net_amount and female_net_amount
## t = 0.64203, df = 36542, p-value = 0.5209
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -23.82403 47.03452
## sample estimates:
## mean of x mean of y
## 2868.076 2856.471The value is more than 0.05 therefore the alternate hypothesis is rejected. There is no significant difference between the net amount spent by male and female customers. The mean net amount for males is 2868.076, and for females, it is 2856.471
7.4.4.3 ANOVA(Analysis of Variance)
We conduct a one-way ANOVA to test whether the average Net Amount spent differs significantly across different age groups.
- Null Hypothesis (\(H_0\)): There is no difference in the Net Amount across age groups.
- Alternative Hypothesis (\(H_1\)): There is a significant difference in the Net Amount across age groups.
## Df Sum Sq Mean Sq F value Pr(>F)
## Age.Group 4 3.705e+07 9262985 3.109 0.0144 *
## Residuals 54995 1.638e+11 2979060
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1There is enough evidence to reject the null hypothesis(p_value <0.05) therefore there is a significant difference in the Net Amount across age groups
7.4.4.4 Chi-Square Test
We perform a chi-square test to determine if there is a relationship between the purchase method (Credit Card, Debit Card, etc.) and whether a discount was availed.
- Null Hypothesis (\(H_0\)): There is no association between the purchase method and discount availed.
- Alternative Hypothesis (\(H_1\)): There is an association between the purchase method and discount availed.
##
## Pearson's Chi-squared test
##
## data: table(ecommerce$Purchase.Method, ecommerce$Discount.Availed)
## X-squared = 3.3007, df = 7, p-value = 0.8559The p-value is 0.8559(above 0.05), indicating no statistically significant association between the purchase method and the availing of discounts.
7.4.4.5 Key Findings
Here are some of the key findings from the project;
- The one-sample t-test suggests that customers spend significantly less than the hypothesized gross amount.
- No significant difference was found in spending between male and female customers based on the two-sample t-test.
- ANOVA results indicate that spending patterns do vary significantly across age groups.
- The Chi-square test shows that the method of purchase has no significant relationship with whether a discount was used.
________________________________________________________________________________